A System for Stress-Testing Estate Plan Docs with A.I. Language Models
Quick Summary
Introduction
I’m a practicing estate planning attorney in San Diego, CA. However, before I began my legal practice, I spent over 10 years writing software. I tend to approach my practice constantly asking how I can leverage my technical skills to deliver better service to my clients. In my previous posts I explored the unique opportunities natural language processing (NLP) tools can provide in the legal context. Here I’d like to share details of a specific internal project I’ve been building for myself for the past few months.
Estate Planning attorneys face a unique challenge: we must craft documents that anticipate countless future possibilities. When drafting a will or trust, we’re essentially creating a legal time capsule designed to withstand unforeseen circumstances that may arise years or decades later.
The traditional approach relies heavily on:
- Attorney experience and memory of past client situations.
- Checklists and templates that cover common scenarios.
- Legal precedent and case studies.
- Manual review processes that are time-consuming and imperfect.
Even the most experienced attorneys struggle to mentally simulate all potential future scenarios, from family dynamics to asset changes to health situations. As a newer attorney, I’ve also been looking for ways to create a systematic check of the documents I create.
The Power of Language Models
A.I. language models such as those that power systems like OpenAI’s ChatGPT, Google’s Gemini tools, or Anthropic’s Claude offer a potentially powerful approach to this problem. These A.I. models can:
- Process and understand complex legal documents in their natural language form
- Generate realistic hypothetical scenarios based on client information
- Evaluate how well a document addresses each scenario
While they do have some reasoning limitations (discussed below), unlike traditional rule-based software, these models can understand nuance and context in legal language, making them very useful for this application.
Technical Architecture: How the System Works
Let me walk through the key components of my internal tool and a high level before going into some details below:
Document Ingestion: The system reads in the trust document being evaluated—this comprehensive legal instrument contains all the provisions, conditions, and instructions that will be stress-tested against future scenarios. The document typically includes sections on asset distribution, trustee powers, beneficiary rights, and special provisions unique to the client's situation.
Client Information Analysis: Next, we process detailed client biographical information that provides crucial context about the individual's family structure, financial situation, and specific concerns. This data helps personalize the evaluation and ensures the scenarios we generate are relevant to the client's actual circumstances rather than generic possibilities.
Scenario Framework Import: Finally, we import structured scenario categories from a Google Sheet that serves as our testing framework. This matrix organizes potential events by both category (family dynamics, asset changes, health situations) and stakeholder (grantor, trustee, beneficiary), creating a comprehensive map of the "what-ifs" that might challenge the document's effectiveness over time.
The system uses a language model (specifically Google's Gemini language model) to analyze client information and extract their top priorities for estate planning. Having clear priorities is important for step #4 below. In retrospect, however, I’ve decided that it’s easy enough for me to articulate these without offloading the task to A.I. (I better know what my client’s priorities are!).
The system creates several sets of tailored hypothetical scenarios by:
1. Starting with generic scenario categories from a spreadsheet (family dynamics, asset changes, health considerations, etc.).
2. Using the generative language model to create client-specific scenarios based on biographical and asset details.
3. Ensuring each scenario is atomic and clearly defined.
The language model performs a "stress test" of the document by:
1. Analyzing how the trust document would handle each hypothetical scenario.
2. Evaluating risk to each client priority (from step #2) on a scale from 0.0 to 1.0.
3. Providing reasoning for each risk assessment.
(This process is modeled after the concept of “unit testing” in the software world.)
Results are saved to a Google spreadsheet for easy review.
There are two components of how the system that I think are worth explaining with more detail and a concrete example…
First, I discuss how I generate scenarios that should provide systematic coverage hypothetical future events worth considering. Second, I discuss how the language model evaluates the trust document against all those scenarios to expose conditions where the document may fail to achieve the client’s goals (what I’m calling the “stress-test”).
1. Building a Comprehensive Set of Hypothetical Scenarios
For this section, I think it’s useful to have a concrete client example to demonstrate the process. Let’s imagine a hypothetical family based on the fairy tale of Snow White (SnowWhiteClientInfo.txt), (thanks to a different model) I have created an entire client background file for Sarah “Snow” White that details her marriage to Prince Florian Charming, their two children, assets, and estate planning concerns. I’ve also quickly written a basic living trust for the Charming family (Trust.pdf).
Now let’s consider how to get the language model to generate hypothetical scenarios the Charming family might face in the future that would test the functionality of the living trust. The overly simplistic approach would be to prompt the system with something like:
“Given this family information in the attached document, generate 10 hypothetical scenarios the family might face in the future.”
This would generate some good scenarios. However, it’s likely that there are important real-world potential scenarios that should be considered that are missing from the generated set. Simply asking the model to generate more scenarios without additional guidance regarding the scope of the scenarios does not address this problem.
My working approach at the moment is to create a spreadsheet where each column header is a stakeholder in the estate plan (Grantor, Trustee, Beneficiary, etc.)….
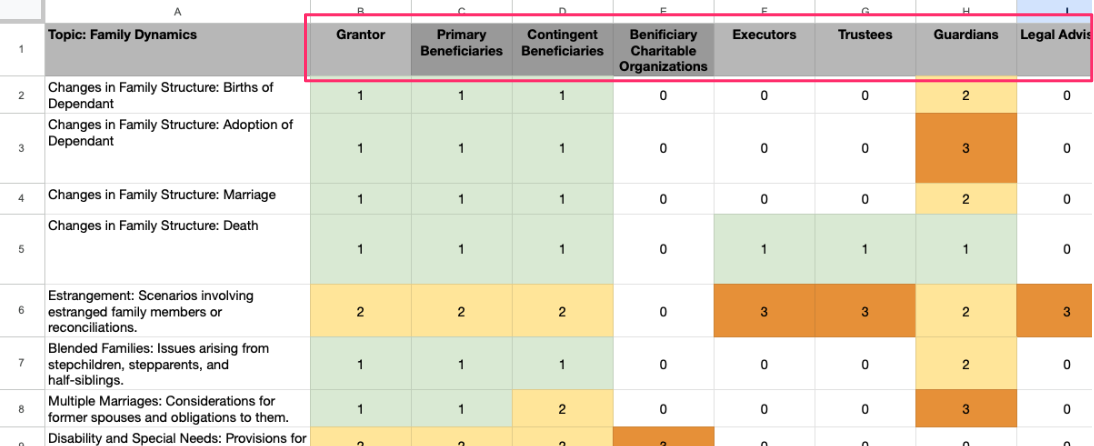
Each row is an event that might occur. I’ve divided these events into different categories so the “Family Dynamics” category includes events such as birth of a child, deaths, incapacitation, etc.) while the “Asset” category includes events such as asset valuation increase, decrease, sale, etc.
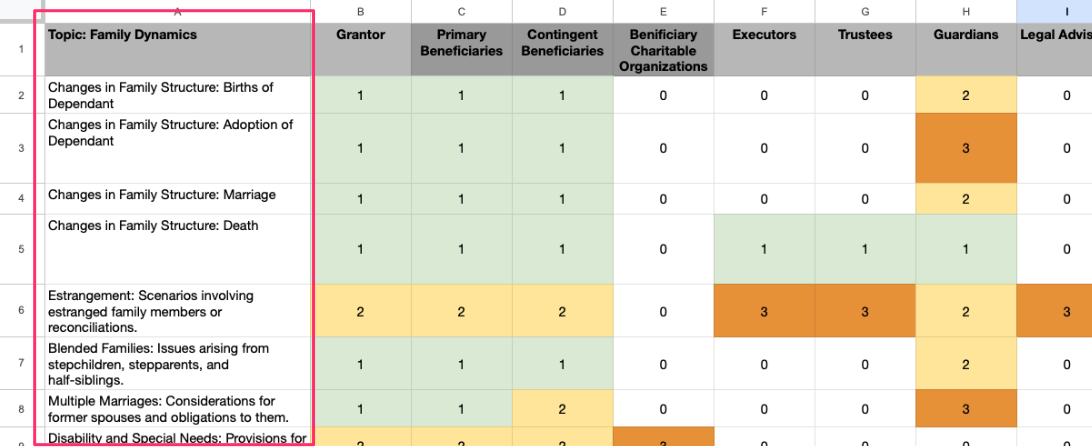
Each cell, then, represents an intersection of a stakeholder and an event (such as “Beneficiary gets married.” C4). I can then write a script that systematically considers each cell and generates a set of hypothetical scenarios at nearly every[1] intersection of stakeholder and event. This way I increase my confidence about the scope of the stress tests to be conducted on the document. The next step is to run the evaluation of the living trust document using these scenarios.
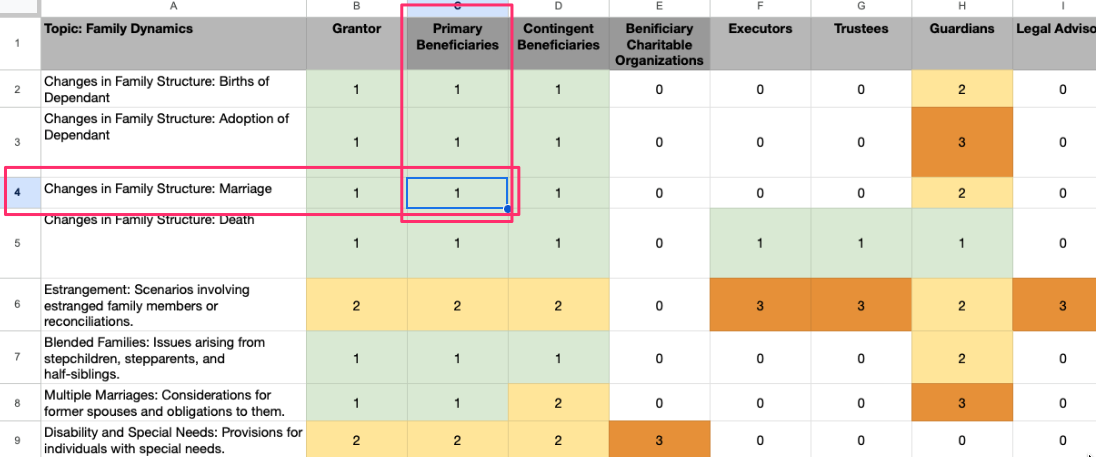
([1] The application supports different depths of analysis (0-3), where 0 represents events that don’t have to be considered and 1 represents events that should always be considered. This allows for quick initial assessments or deep comprehensive reviews.)
Stress-Testing the Living Trust
Now that I have an extensive list of scenarios, it’s time to see how this living trust performs if these scenarios were to occur. I want a way to grade the performance of the living trust, but the key question is, what metric do we use for this evaluation?
Between the client and I, we should have a clear set of client priorities in the context of creating their estate plan. Some of these priorities will be rather universal (“Protect against avoidable negative tax impacts.”), others will be unique to each client. In Sarah (“Snow”) White’s case, a clear priority is providing for the future needs of Rose and Leo Charming, their children.
Now I can feed three critical inputs to the language model (the trust, a hypothetical scenario, a client priority) and ask the language model to consider the exposure of risk the client has to that hypothetical scenario given the current draft of the trust document.[1] This risk evaluation is presented as a number between 0.0 and 1.0 where 1.0 represents a high level of risk that the trust document does not adequately address this scenario and 0.0 represents little to no risk to the stated client priority.
Generally, reasoning language models at this stage of development should not be used as calculators. So, I do not put much faith in the actual number that the model outputs for the risk score in the absolute sense. In fact, I often run the same individual scenario input and get a different number risk score output each time. What is more important however, is that when a set of scenarios are input into the model, the model’s evaluation of the risk each scenario presents relative to other scenarios in the set is consistent. Usually, what I’m looking for are scenarios that have an elevated risk score. The model consistently will flag the same scenarios that need closer consideration for potential edits to the living trust.
([1] I do provide some guidance (not discussed here for brevity) to the model regarding how to evaluate risk.)
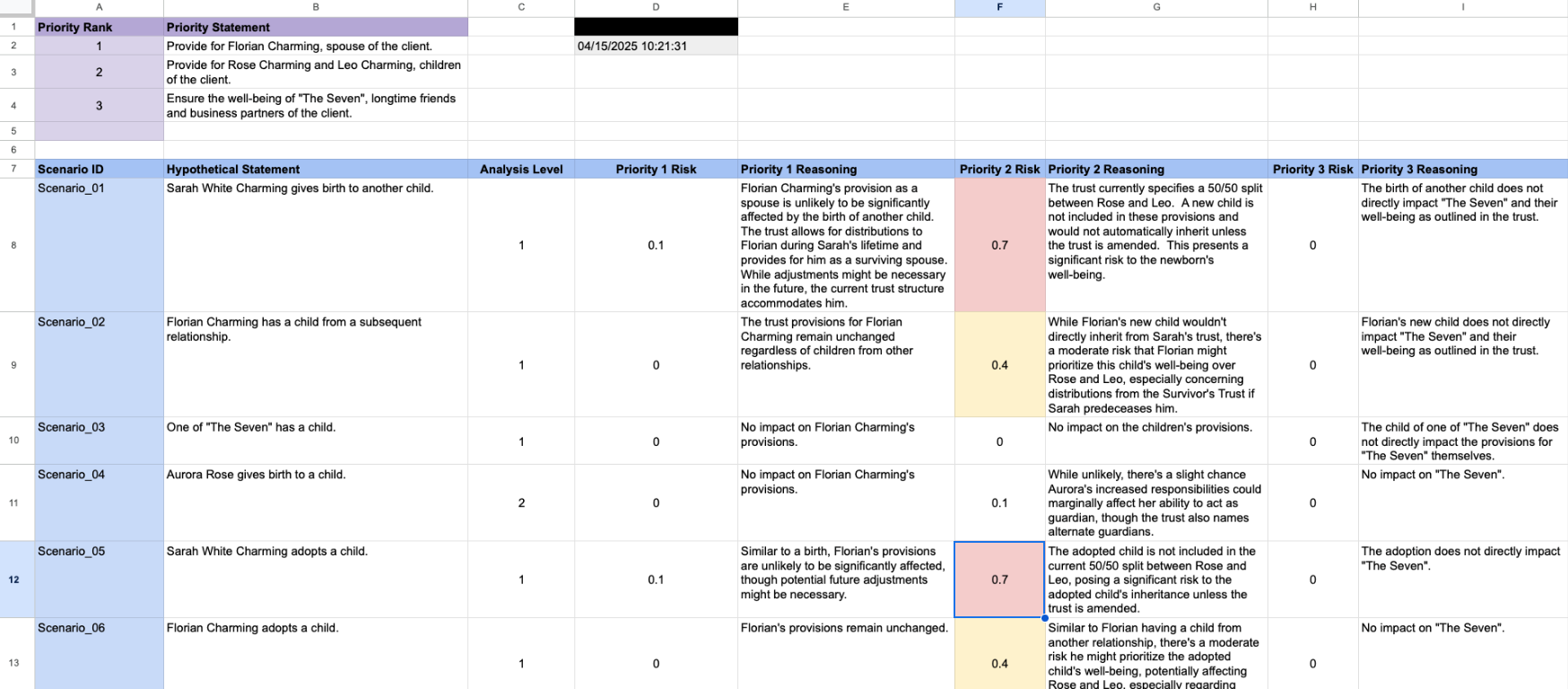
Let’s see how this functions in the case of Sarah White. You can see in the spreadsheet that cell F12 has a comparatively high risk score of 0.7 (and colored red). This correlates to Scenario_05: “Sarah White Charming adopts a child.” This is under the column providing scores for the family’s second estate planning priority. At the top of the spreadsheet in purple is a list of the three articulated priorities. This priority is described as “Provide for Rose Charming, and Leo Charming, children of the client.”
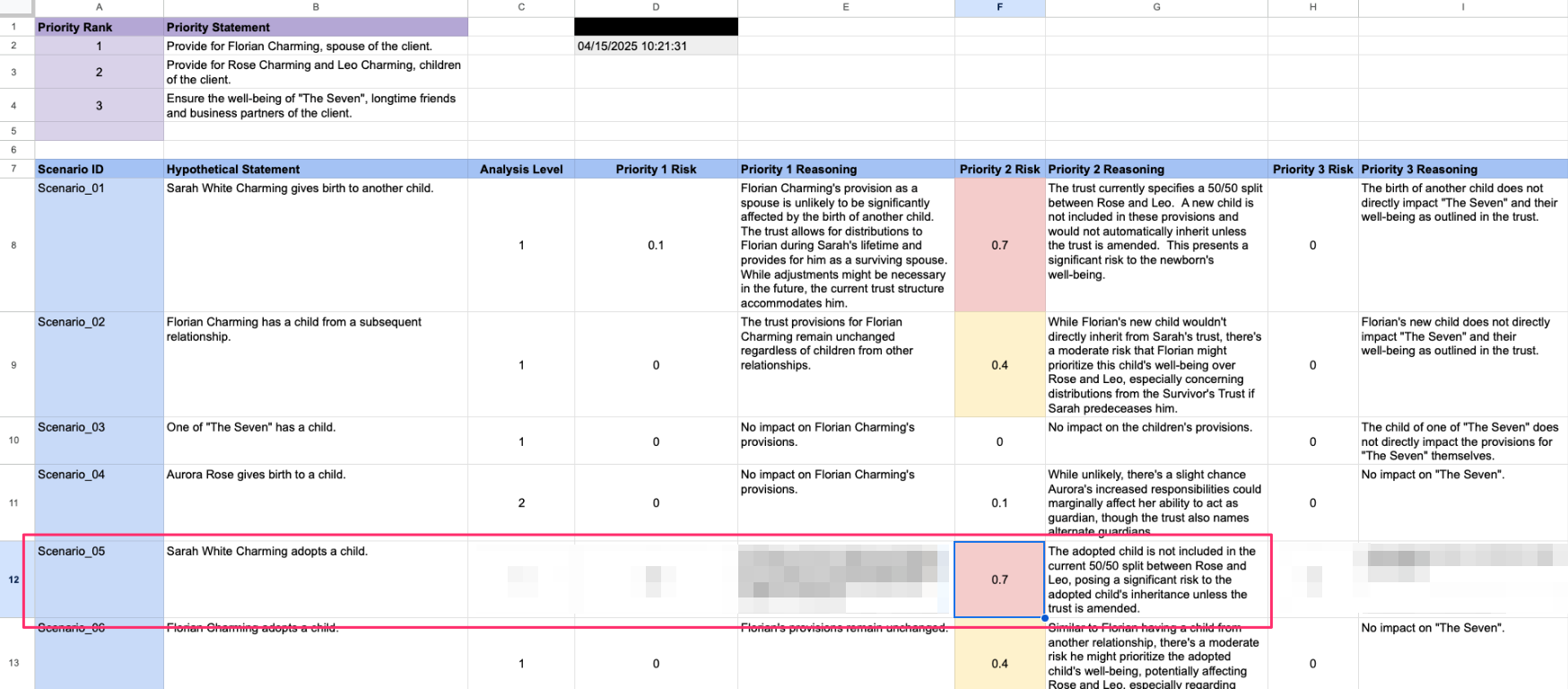
The living trust as currently drafted divides the residuary estate providing 50% to Rose and 50% for Leo. Therefore, I believe the risk score provided by the language model is appropriate in that it draws attention to the fact that if the family adopts a third child, that child may have a problem with an inheritance from the trust without an amendment. (Yes, you’ll notice the same basic concern logically exists if Snow White gives birth to another child.)
The Impact on My Legal Practice
This tool has transformed my estate planning practice in several ways:
- Comprehensive Coverage: I can now evaluate documents against hundreds of hypothetical scenarios instead of the handful I might manually consider.
- Client Education: The results provide a clear basis for discussing potential risks with clients.
- Quality Assurance: Even for experienced attorneys, the system catches edge cases and subtle document weaknesses.
- Time Efficiency: The system can test potentially hundreds of hypothetical scenarios in seconds.
It’s important to note that this evaluation system is not a replacement for my own due diligence regarding drafting and review of the estate plan. Rather, this is a useful supplement to my manual work. Indeed, it’s important to take into account the legal reasoning ability of the models themselves. Still the ability of the system to articulate and consider hundreds of hypothetical scenarios in a matter of seconds is an incredible asset in double-checking my work.
Next Steps
This system is far from perfect nor is it complete. As an initial proof-of-concept it has already been useful to my practice, but there are several ways I plan to improve and expand on it. The improvements I plan to make fall into the following categories:
- Currently, I'm only processing one legal document at a time. But when considering how a circumstance might affect the client, it's more useful for the system to consider ALL documents in the estate plan (trust, will, power of attorney, etc.) and how they work together.
- I'm current passing in raw document text into the model prompt. But raw text ignores document layout and styling (such as headings, bold, italics, etc.) which often have legal significance. So, it might be better to use a more visual model than a purely text-based approach to document ingestion.
- The workflow also takes as input a text file that consists of background information specific to the client. In this case, it's Snow White's family information, asset information, etc. Ideally, this information would be ingested from actual client file in Clio and Decision Vault, etc.
- Obviously, a key components here is the evaluation done by the language model of the legal document. Fine-tuning the model to the specific legal domain and jurisdiction is an important consideration to improve the output. There should be some feedback mechanism so that as the user reviews the output and approve or disapprove of results, that data can flow back into improving the model itself.
- On a related note, there is not reason a single model should be solely responsible for evaluation. Using multiple different models would allow for some very useful A-B testing and improvement.
- The current output Google sheet is useful to me as a technical lawyer and not something I would ever put in front of a client (or a non-technical lawyer). I would like to design a simplified, user-friendly report.
- The reasoning for each risk score does not currently include citation/attribution to specific text and sources which is necessary.
- I want to move away from numerical risk scores (0.0-1.0) to something that looks less precise because those numbers make the score look more precise than it is.
It's worth noting that at the moment, this system is mostly offline for security reasons. While output analysis is stored in secured Google sheets, client information and documents remain on my local machine. I've had to generate the imaginary Snow White estate plan and client file for testing and development of the system. I also don't use any client information with A.I. systems without checking the security safeguards of those systems and their privacy policies. I also make sure to get client consent before doing so.
As much as I would like to have a production system that clients could engage with directly, I don't see that happening in the near future. What is more likely, is a production system for internal use to a law practice using language models that can be locally hosted so all information processing happens internally. It will be interesting to explore the trade-offs of performance of local models vs. remote cutting-edge models.
Conclusion
By combining legal expertise with artificial intelligence, we can create more robust estate planning documents that better protect our clients’ wishes and priorities. This approach represents just the beginning of how AI can augment and enhance legal practice rather than replace attorney judgment.